
In this post we’ll have a final look on our little PL/SQL program as this is going to be an end to our Beginner's mistakes in PL/SQL series ... for now ;).
We’ll going to take a look at last (yet very important) structural flaw in our PL/SQL code. If we take a closer look at our code, we’ll discover that there are several function calls in main data fetch cycle.
We are talking about functions:
- get_indexes
- has_nullable
- has_default
- get_columns
If we look at them, we’ll discover that pure goal of these functions is to produce concatenated list of indexes and columns for particular object or to provide a flag on existence of nullable columns and defaults.
This approach has a HUGE negative impact on performance. Reason for that is an event we call “the context switch”. This event occurs because Oracle has two language processing engines:
- Database engine – which has SQL statement executor (he knows how to execute and process SQL statements)
- PL/SQL engine – which is capable of processing PL/SQL procedural language
Here is a nice picture of how your PL/SQL code processing looks like in Oracle:
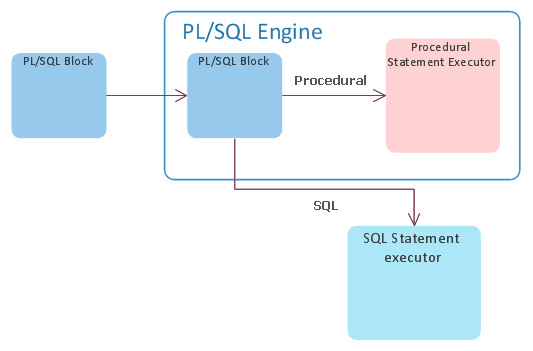
So, every time PL/SQL engine sees an SQL statement, he basically takes it and sends it to the database engine for execution and waits for results. This act of “outsourcing” is what is called context switch and is quite CPU expensive. This phenomenon is not only about execution your SQL but also about receiving data from it. In our example, the code creator is nicely fetching data from main select by 5000 rows into an array, so he does not need to ask SQL engine for every row. He just asks for next batch of 5000 hence minimizing number of context switches while fetching the data.
Our goal is that if we have to call a SQL statement, we want to get most out of it. We want to get our data, play with it, and when we are done, ask for next batch of them.
It seems that in this case the programmer didn’t see any efficient way (or any way at all) how to get the information he needs from main query. My guess is that the issue here was the pivoting. He didn’t know how to take the list of indexes (or columns) and produce that list as one line. Because this is a simple concatenation problem; one function comes to my mind – LISTAGG. It’s basically an aggregation by concatenation function. Only limitation we have here is that LISTAGG cannot produce string longer than 4000 bytes (for purposes of this demonstration we’ll pretend it’ll never happen :) ).
So, we know now that we CAN put EVERY function we listed above into our main SQL statement and thus eliminating number of context switches by huge amount. We'll not only eliminate the function calls but also the bunch of context switches that are produced by FOR cycles in those functions. Here is how it’s done:
1. We’ll have to change our data model a little bit so we can store few new columns
DROP TABLE my_data_tmp
/
CREATE GLOBAL TEMPORARY TABLE my_data_tmp
( table_name VARCHAR2(30) NOT NULL,
partitioned VARCHAR2(3),
temporary VARCHAR2(1),
index_list VARCHAR2(4000),
has_nullable VARCHAR2(1),
has_data_default VARCHAR2(1),
column_list VARCHAR2(4000)
) ON COMMIT DELETE ROWS
/
/
CREATE GLOBAL TEMPORARY TABLE my_data_tmp
( table_name VARCHAR2(30) NOT NULL,
partitioned VARCHAR2(3),
temporary VARCHAR2(1),
index_list VARCHAR2(4000),
has_nullable VARCHAR2(1),
has_data_default VARCHAR2(1),
column_list VARCHAR2(4000)
) ON COMMIT DELETE ROWS
/
2. Now we can rewrite our main query as follows
INSERT INTO my_data_tmp
SELECT tabs.table_name,
tabs.partitioned,
tabs.temporary,
idxs.index_list,
COALESCE(CASE WHEN cols.count_nullable > 1 THEN 'Y' ELSE 'N' END, 'N'),
COALESCE(CASE WHEN cols.count_data_default > 1 THEN 'Y' ELSE 'N' END, 'N'),
cols.column_list
FROM my_tables tabs
LEFT OUTER JOIN
(SELECT /*+ PUSH_PRED */
object_id_table,
LISTAGG(index_name,',') WITHIN GROUP (ORDER BY index_name) index_list
FROM my_table_indexes
GROUP BY object_id_table
) idxs
ON (idxs.object_id_table = tabs.object_id)
LEFT OUTER JOIN
(SELECT /*+ PUSH_PRED */
object_id,
LISTAGG(column_name,',') WITHIN GROUP (ORDER BY column_id) column_list,
COUNT(CASE WHEN nullable = 'Y' THEN 1 ELSE NULL END) count_nullable,
COUNT(CASE WHEN data_default = 'Y' THEN 1 ELSE NULL END) count_data_default
FROM my_table_columns
GROUP BY object_id
) cols
ON (cols.object_id = tabs.object_id);
SELECT tabs.table_name,
tabs.partitioned,
tabs.temporary,
idxs.index_list,
COALESCE(CASE WHEN cols.count_nullable > 1 THEN 'Y' ELSE 'N' END, 'N'),
COALESCE(CASE WHEN cols.count_data_default > 1 THEN 'Y' ELSE 'N' END, 'N'),
cols.column_list
FROM my_tables tabs
LEFT OUTER JOIN
(SELECT /*+ PUSH_PRED */
object_id_table,
LISTAGG(index_name,',') WITHIN GROUP (ORDER BY index_name) index_list
FROM my_table_indexes
GROUP BY object_id_table
) idxs
ON (idxs.object_id_table = tabs.object_id)
LEFT OUTER JOIN
(SELECT /*+ PUSH_PRED */
object_id,
LISTAGG(column_name,',') WITHIN GROUP (ORDER BY column_id) column_list,
COUNT(CASE WHEN nullable = 'Y' THEN 1 ELSE NULL END) count_nullable,
COUNT(CASE WHEN data_default = 'Y' THEN 1 ELSE NULL END) count_data_default
FROM my_table_columns
GROUP BY object_id
) cols
ON (cols.object_id = tabs.object_id);
I had to use PUSH_PRED hint to force Oracle to push object_id into the subquery so that everything is nice and tidy.
As you can see we were also able to easily get all the flags we needed inside the main query without any extra performance hit. We just took advantage of data we had to read anyway.
Now let us compare run times of old and new version of our code after all the work we had done on it.
Old version:
System FLUSH altered.
PL/SQL procedure successfully completed.
Start tmp 19:55:10
End tmp 19:55:10
Start blob 19:55:10
Exported 3306 rows
End blob 19:56:05
New version:
System FLUSH altered.
PL/SQL procedure successfully completed.
Tmp loaded in .71 sec
Exported 3306 rows in .16 sec
Ok that’s 55 seconds vs 0.87 of second. I think that the result is so obvious that we don’t even have to check for stats.
You can download the final package code here:
data_to_ascii.pkb
Thank you for bearing with me through all 4 parts of this series and see you soon.
No comments:
Post a Comment